Микроархитектура
В компьютерной технике микроархитектура (иногда сокращенно µarch или uarch) - это описание электрической схемы компьютера, центрального процессора или процессора цифровых сигналов, достаточное для полного описания работы аппаратного обеспечения.…
В компьютерной технике микроархитектура (иногда сокращенно µarch или uarch) - это описание электрической схемы компьютера, центрального процессора или процессора цифровых сигналов, достаточное для полного описания работы аппаратного обеспечения.
Ученые используют термин "организация компьютера", в то время как люди в компьютерной индустрии чаще говорят "микроархитектура". Микроархитектура и архитектура набора команд (ISA) вместе составляют область компьютерной архитектуры.
Галерея изображений
1 Изображение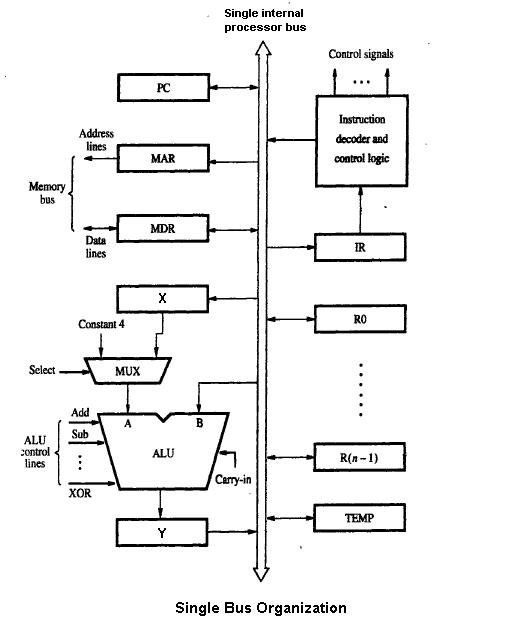
Происхождение термина
Компьютеры используют микропрограммирование логики управления с 1950-х годов. Центральный процессор декодирует инструкции и посылает сигналы по соответствующим путям с помощью транзисторных переключателей. Биты внутри слов микропрограммы управляли процессором на уровне электрических сигналов.
Термин: "микроархитектура" использовался для описания блоков, которые управлялись словами микропрограммы, в отличие от термина: "архитектура", который был видимым и документированным для программистов. В то время как архитектура обычно должна была быть совместима между поколениями аппаратного обеспечения, лежащая в основе микроархитектура могла быть легко изменена.
Отношение к архитектуре набора команд
Микроархитектура связана с архитектурой набора команд, но не тождественна ей. Архитектура набора инструкций близка к программной модели процессора, как ее видит программист на языке ассемблера или автор компилятора, которая включает модель исполнения, регистры процессора, режимы адресации памяти, форматы адресов и данных и т. д. Микроархитектура (или организация компьютера) в основном является структурой более низкого уровня и поэтому управляет большим количеством деталей, которые скрыты в модели программирования. Она описывает внутренние части процессора и то, как они работают вместе для реализации архитектурной спецификации.
Микроархитектурные элементы могут быть любыми - от отдельных логических вентилей, регистров, таблиц поиска, мультиплексоров, счетчиков и т.д. до полных АЛУ, FPU и даже более крупных элементов. Уровень электронных схем, в свою очередь, может быть разделен на детали транзисторного уровня, например, какие основные структуры построения затворов используются и какие типы логической реализации (статические/динамические, количество фаз и т.д.) выбраны, в дополнение к фактической логической конструкции, используемой для их построения.
Несколько важных моментов:
- Одна микроархитектура, особенно если она включает микрокод, может быть использована для реализации множества различных наборов команд путем изменения магазина управления. Однако это может быть довольно сложно, даже если упростить микрокод и/или структуры таблиц в ПЗУ или PLA.
- Две машины могут иметь одинаковую микроархитектуру и, соответственно, одинаковую блок-схему, но совершенно разные аппаратные реализации. Это управляет как уровнем электронной схемы, так и еще более физическим уровнем производства (как микросхем, так и дискретных компонентов).
- Машины с разными микроархитектурами могут иметь одинаковую архитектуру набора команд, и поэтому обе способны выполнять одни и те же программы. Новые микроархитектуры и/или схемотехнические решения, а также прогресс в производстве полупроводников позволяют новым поколениям процессоров достигать более высокой производительности.
Упрощенные описания
Очень упрощенное описание высокого уровня - распространенное в маркетинге - может показывать только достаточно базовые характеристики, такие как ширина шины, наряду с различными типами блоков исполнения и других больших систем, таких как предсказание ветвлений и кэш-память, изображенных в виде простых блоков - возможно, с указанием некоторых важных атрибутов или характеристик. Некоторые детали структуры конвейера (например, выборка, декодирование, присвоение, выполнение, запись-возврат) иногда также могут быть включены.
Аспекты микроархитектуры
Конвейерный путь данных является наиболее часто используемой конструкцией пути данных в микроархитектуре на сегодняшний день. Эта техника используется в большинстве современных микропроцессоров, микроконтроллеров и ЦСП. Конвейерная архитектура позволяет нескольким инструкциям накладываться друг на друга при выполнении, подобно ассемблеру. Конвейер включает в себя несколько различных этапов, которые являются основополагающими при разработке микроархитектуры. Некоторые из этих этапов включают выборку инструкций, декодирование инструкций, выполнение и обратную запись. Некоторые архитектуры включают и другие этапы, например, доступ к памяти. Проектирование конвейеров является одной из центральных задач микроархитектуры.
Исполнительные блоки также важны для микроархитектуры. К исполнительным блокам относятся блоки арифметической логики (ALU), блоки с плавающей запятой (FPU), блоки загрузки/сохранения и предсказания ветвлений. Эти блоки выполняют операции или вычисления процессора. Выбор количества блоков исполнения, их латентность и пропускная способность являются важными задачами микроархитектурного проектирования. Размер, задержка, пропускная способность и подключение памяти в системе также являются микроархитектурными решениями.
Решения по проектированию на уровне системы, такие как включение или невключение периферийных устройств, например, контроллеров памяти, можно считать частью процесса проектирования микроархитектуры. Сюда входят решения об уровне производительности и возможностях подключения этих периферийных устройств.
В отличие от архитектурного проектирования, где главной целью является конкретный уровень производительности, при микроархитектурном проектировании больше внимания уделяется другим ограничениям. Внимание должно быть уделено таким вопросам, как:
- Площадь чипа/стоимость.
- Потребляемая мощность.
- Логическая сложность.
- Простота подключения.
- Изготавливаемость.
- Простота отладки.
- Проверяемость.
Микроархитектурные концепции
В целом, все центральные процессоры, однокристальные микропроцессоры или многокристальные реализации, выполняют программы, выполняя следующие действия:
- Прочитайте инструкцию и расшифруйте ее.
- Найдите любые связанные данные, необходимые для обработки инструкции.
- Обработайте инструкцию.
- Запишите результаты.
Усложняет эту простую на вид серию шагов тот факт, что иерархия памяти, включающая кэширование, основную память и энергонезависимое хранилище, например, жесткие диски, (где находятся программные инструкции и данные) всегда была медленнее, чем сам процессор. Шаг (2) часто вводит задержку (в терминах процессора часто называемую "пробуксовкой"), пока данные поступают по компьютерной шине. Большое количество исследований было направлено на разработку дизайна, позволяющего избежать этих задержек, насколько это возможно. В течение многих лет основной целью проектирования было параллельное выполнение большего количества инструкций, что увеличивало эффективную скорость выполнения программы. Эти усилия привели к появлению сложных логических и схемных структур. В прошлом такие методы могли быть реализованы только на дорогих мейнфреймах или суперкомпьютерах из-за большого количества схем, необходимых для этих методов. По мере развития производства полупроводников все больше и больше таких методов можно было реализовать на одном полупроводниковом чипе.
Далее следует обзор микроархитектурных методов, распространенных в современных процессорах.
Выбор набора инструкций
Выбор используемой архитектуры набора инструкций значительно влияет на сложность реализации высокопроизводительных устройств. На протяжении многих лет разработчики компьютеров делали все возможное для упрощения наборов инструкций, чтобы обеспечить более высокую производительность реализаций, экономя усилия и время разработчиков для функций, улучшающих производительность, вместо того, чтобы тратить их на усложнение набора инструкций.
Проектирование наборов команд развивалось от CISC, RISC, VLIW, EPIC. Архитектуры, которые занимаются параллелизмом данных, включают SIMD и векторы.
Конвейерная обработка инструкций
Одним из первых и наиболее мощных методов повышения производительности является использование конвейера инструкций. Ранние модели процессоров выполняли все описанные выше шаги для одной инструкции, прежде чем переходить к следующей. Большая часть схем процессора оставалась незадействованной на каждом шаге; например, схема декодирования инструкции простаивала во время выполнения и так далее.
Конвейеры повышают производительность, позволяя нескольким инструкциям проходить через процессор одновременно. В том же базовом примере процессор начнет декодировать (шаг 1) новую инструкцию, пока предыдущая ожидает результатов. Таким образом, одновременно в "полете" могут находиться до четырех инструкций, что позволяет процессору работать в четыре раза быстрее. Хотя на выполнение любой инструкции требуется столько же времени (все еще есть четыре шага), процессор в целом "выводит из работы" инструкции гораздо быстрее и может работать с гораздо более высокой тактовой частотой.
Кэш
Усовершенствования в производстве микросхем позволили разместить больше схем на одном кристалле, и разработчики начали искать способы их использования. Одним из наиболее распространенных способов было добавление все большего объема кэш-памяти на чип. Кэш-память - это очень быстрая память, память, доступ к которой осуществляется за несколько циклов по сравнению с тем, что требуется для обращения к основной памяти. Процессор включает контроллер кэша, который автоматизирует чтение и запись из кэша. Если данные уже находятся в кэше, они просто "появляются", если же нет, то процессор "замирает", пока контроллер кэша считывает их.
RISC-проекты начали добавлять кэш-память в середине-конце 1980-х годов, зачастую ее общий объем составлял всего 4 КБ. Со временем это число увеличивалось, и сейчас типичные процессоры имеют около 512 КБ, а более мощные процессоры оснащаются 1 или 2 или даже 4, 6, 8 или 12 МБ, организованными на нескольких уровнях иерархии памяти. Вообще говоря, больше кэш-памяти означает больше скорости.
Кэши и конвейеры идеально подходят друг другу. Раньше не было особого смысла строить конвейер, который мог бы работать быстрее, чем задержка доступа к внечиповой кэш-памяти. Использование кэш-памяти на кристалле вместо этого означало, что конвейер мог работать со скоростью латентности доступа к кэш-памяти, т.е. гораздо меньший промежуток времени. Это позволило увеличить рабочую частоту процессоров гораздо быстрее, чем частоту внечиповой памяти.
Предсказание ветвей и спекулятивное выполнение
Застой конвейера и сброс из-за ветвлений - две основные вещи, мешающие достижению более высокой производительности за счет параллелизма на уровне инструкций. С момента, когда декодер инструкций процессора обнаружил, что встретил инструкцию условного ветвления, до момента, когда может быть считано решающее значение регистра перехода, конвейер может застопориться на несколько тактов. В среднем, каждая пятая выполненная инструкция является ветвлением, так что это большое количество остановок. Если ответвление выполнено, это еще хуже, так как в этом случае все последующие инструкции, которые были в конвейере, должны быть очищены.
Такие техники, как предсказание ветвлений и спекулятивное выполнение, используются для уменьшения штрафов за ветвления. Предсказание ответвлений - это когда аппаратное обеспечение делает обоснованные предположения о том, будет ли выполнено конкретное ответвление. Это предположение позволяет аппаратному обеспечению выполнять предварительную выборку инструкций, не дожидаясь чтения регистра. Спекулятивное выполнение - это дальнейшее усовершенствование, при котором код по предсказанному пути выполняется до того, как станет известно, следует ли выполнять ответвление или нет.
Внеочередное выполнение
Добавление кэш-памяти уменьшает частоту или продолжительность задержек из-за ожидания получения данных из иерархии основной памяти, но не избавляет от этих задержек полностью. В ранних разработках промах в кэше заставлял контроллер кэша останавливать процессор и ждать. Конечно, в программе может быть еще какая-то инструкция, данные которой в этот момент доступны в кэше. Выполнение не по порядку позволяет обработать готовую инструкцию, пока более старая инструкция ожидает в кэше, а затем изменить порядок результатов, чтобы казалось, что все произошло в запрограммированном порядке.
Суперскалярный
Даже несмотря на всю сложность и дополнительные вентили, необходимые для поддержки концепций, описанных выше, усовершенствования в производстве полупроводников вскоре позволили использовать еще больше логических вентилей.
В приведенной схеме процессор обрабатывает части одной инструкции за один раз. Компьютерные программы могли бы выполняться быстрее, если бы несколько инструкций обрабатывались одновременно. Именно этого и добиваются суперскалярные процессоры за счет репликации функциональных блоков, таких как АЛУ. Репликация функциональных блоков стала возможной только тогда, когда площадь интегральной схемы (иногда называемой "матрицей") однопроцессорного процессора перестала ограничивать возможности надежного производства. К концу 1980-х годов на рынке начали появляться суперскалярные процессоры.
В современных конструкциях обычно встречаются два блока загрузки, один блок хранения (многие инструкции не имеют результатов для хранения), два или более целочисленных математических блока, два или более блоков с плавающей запятой и часто какой-то SIMD-блок. Логика выдачи инструкций усложняется за счет считывания огромного списка инструкций из памяти и передачи их различным блокам выполнения, которые в этот момент простаивают. Затем результаты собираются и упорядочиваются в конце.
Переименование регистров
Переименование регистров относится к технике, используемой для того, чтобы избежать ненужного серийного выполнения инструкций программы из-за повторного использования одних и тех же регистров этими инструкциями. Предположим, у нас есть несколько групп инструкций, которые будут использовать один и тот же регистр, один набор инструкций выполняется первым, чтобы оставить регистр другому набору, но если другому набору присвоен другой аналогичный регистр, оба набора инструкций могут выполняться параллельно.
Многопроцессорность и многопоточность
Из-за растущего разрыва между рабочей частотой процессора и временем доступа к DRAM ни одна из техник, улучшающих параллелизм на уровне инструкций (ILP) в рамках одной программы, не могла преодолеть длительные задержки, возникающие при получении данных из основной памяти. Кроме того, большое количество транзисторов и высокие рабочие частоты, необходимые для более продвинутых методов ILP, требовали таких уровней рассеиваемой мощности, которые уже не могли быть дешево охлаждены. По этим причинам новые поколения компьютеров начали использовать более высокие уровни параллелизма, которые существуют за пределами одной программы или программного потока.
Эта тенденция иногда известна как "вычисления с пропускной способностью". Эта идея зародилась на рынке мейнфреймов, где при обработке транзакций в режиме онлайн особое внимание уделялось не только скорости выполнения одной транзакции, но и способности обрабатывать большое количество транзакций одновременно. Поскольку в последнее десятилетие значительно возросло число приложений, основанных на транзакциях, таких как сетевая маршрутизация и обслуживание веб-сайтов, компьютерная индустрия вновь обратила внимание на вопросы производительности и пропускной способности.
Одним из способов достижения параллелизма является использование многопроцессорных систем - компьютерных систем с несколькими центральными процессорами. В прошлом это было характерно только для высокопроизводительных мэйнфреймов, но теперь небольшие (2-8) многопроцессорные серверы стали обычным явлением для рынка малого бизнеса. Для крупных корпораций распространены многопроцессорные серверы большого масштаба (16-256). С 1990-х годов появились даже персональные компьютеры с несколькими процессорами.
Развитие полупроводниковой технологии позволило уменьшить размер транзисторов; появились многоядерные процессоры, в которых несколько процессоров реализованы на одном кремниевом чипе. Первоначально они использовались в микросхемах, предназначенных для встраиваемых систем, где более простые и компактные процессоры позволяли разместить несколько инстанций на одном кремнии. К 2005 году полупроводниковая технология позволила серийно производить двойные настольные процессоры высокого класса на чипах CMP. Некоторые конструкции, такие как UltraSPARC T1, использовали более простые (скалярные, порядковые) конструкции, чтобы разместить больше процессоров на одном куске кремния.
В последнее время все большую популярность приобретает еще одна техника - многопоточность. При многопоточности, когда процессор должен получить данные из медленной системной памяти, вместо того, чтобы ждать, пока данные придут, процессор переключается на другую программу или поток программ, которые готовы к выполнению. Хотя это не ускоряет конкретную программу/поток, это увеличивает общую пропускную способность системы за счет сокращения времени простоя процессора.
Концептуально многопоточность эквивалентна переключению контекста на уровне операционной системы. Разница заключается в том, что многопоточный процессор может выполнить переключение потоков за один цикл процессора вместо сотен или тысяч циклов процессора, которые обычно требуются для контекстного переключения. Это достигается путем дублирования аппаратных средств состояния (таких как регистровый файл и программный счетчик) для каждого активного потока.
Еще одним усовершенствованием является одновременная многопоточность. Эта техника позволяет суперскалярным процессорам выполнять инструкции разных программ/потоков одновременно в одном цикле.
Похожие страницы
- Микропроцессор
- Микроконтроллер
- Многоядерный процессор
- Цифровой сигнальный процессор
- Конструкция процессора
- Datapath
- параллелизм на уровне инструкций (ILP)
Вопросы и ответы
В: Что такое микроархитектура?
О: Микроархитектура - это описание электрической схемы компьютера, центрального процессора или процессора цифровых сигналов, достаточное для полного описания работы аппаратного обеспечения.
В: Как ученые обозначают это понятие?
О: Ученые используют термин "организация компьютера", когда говорят о микроархитектуре.
В: Как люди в компьютерной индустрии относятся к этому понятию?
О: Люди в компьютерной индустрии чаще говорят "микроархитектура", когда имеют в виду это понятие.
В: Какие две области составляют компьютерную архитектуру?
О: Микроархитектура и архитектура набора команд (ISA) вместе составляют область компьютерной архитектуры.
В: Что означает ISA?
О: ISA расшифровывается как Instruction Set Architecture.
В: Что означает µarch? О: µArch означает микроархитектура.
Связанные статьи
Автор
AlegsaOnline.com Микроархитектура Leandro Alegsa
URL: https://ru.alegsaonline.com/art/64586
Источники
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture